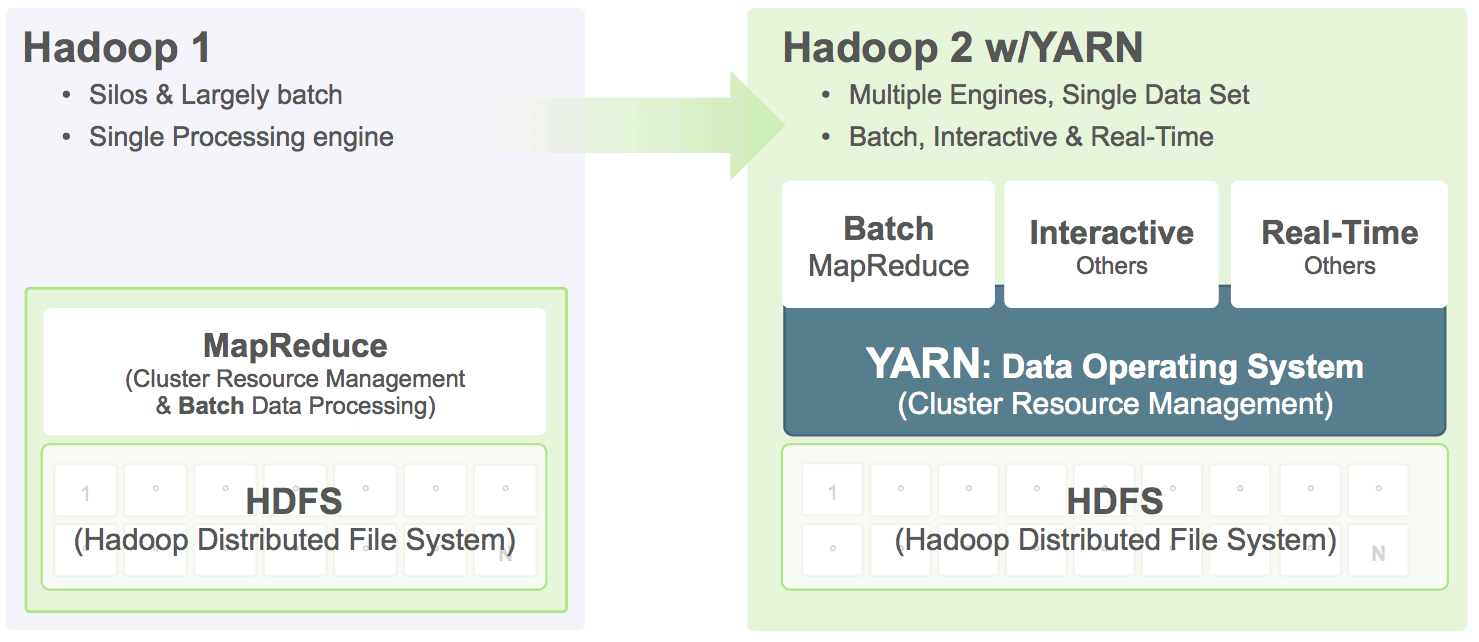
YARN takes the
resource management capabilities that were in MapReduce and packages
them so they can be used by new engines. This also streamlines
MapReduce to do what it does best, process data. With YARN, you can now
run multiple applications in Hadoop, all sharing a common resource
management.
In this blog post we’ll walk through how to plan for and configure
processing capacity in your enterprise HDP 2.0 cluster deployment. This
will cover YARN and MapReduce 2. We’ll use an example physical cluster
of slave nodes each with 48 GB ram, 12 disks and 2 hex core CPUs (12
total cores).
 YARN
takes into account all the available compute resources on each machine
in the cluster. Based on the available resources, YARN will negotiate
resource requests from applications (such as MapReduce) running in the
cluster. YARN then provides processing capacity to each application by
allocating Containers. A Container is the basic unit of processing
capacity in YARN, and is an encapsulation of resource elements (memory,
cpu etc.).
YARN
takes into account all the available compute resources on each machine
in the cluster. Based on the available resources, YARN will negotiate
resource requests from applications (such as MapReduce) running in the
cluster. YARN then provides processing capacity to each application by
allocating Containers. A Container is the basic unit of processing
capacity in YARN, and is an encapsulation of resource elements (memory,
cpu etc.).Configuring YARN
In a Hadoop cluster, it’s vital to balance the usage of RAM, CPU and
disk so that processing is not constrained by any one of these cluster
resources. As a general recommendation, we’ve found that allowing for
1-2 Containers per disk and per core gives the best balance for cluster
utilization. So with our example cluster node with 12 disks and 12
cores, we will allow for 20 maximum Containers to be allocated to each
node.
Each machine in our cluster has 48 GB of RAM. Some of this RAM should
be reserved for Operating System usage. On each node, we’ll assign 40
GB RAM for YARN to use and keep 8 GB for the Operating System. The
following property sets the maximum memory YARN can utilize on the node:
In
yarn-site.xml
1
2
| <name>yarn.nodemanager.resource.memory-mb</name><value>40960</value> |
The next step is to provide YARN guidance on how to break up the
total resources available into Containers. You do this by specifying the
minimum unit of RAM to allocate for a Container. We want to allow for a
maximum of 20 Containers, and thus need (40 GB total RAM) / (20 # of
Containers) = 2 GB minimum per container:
In
yarn-site.xml
1
2
| <name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value> |
YARN will allocate Containers with RAM amounts greater than the
yarn.scheduler.minimum-allocation-mb.Configuring MapReduce 2
MapReduce 2 runs on top of YARN and utilizes YARN Containers to schedule and execute its map and reduce tasks.
When configuring MapReduce 2 resource utilization on YARN, there are three aspects to consider:
- Physical RAM limit for each Map And Reduce task
- The JVM heap size limit for each task
- The amount of virtual memory each task will get
You can define how much maximum memory each Map and Reduce task will
take. Since each Map and each Reduce will run in a separate Container,
these maximum memory settings should be at least equal to or more than
the YARN minimum Container allocation.
For our example cluster, we have the minimum RAM for a Container (
yarn.scheduler.minimum-allocation-mb) = 2 GB. We’ll thus assign 4 GB for Map task Containers, and 8 GB for Reduce tasks Containers.
In
mapred-site.xml:
1
2
3
4
| <name>mapreduce.map.memory.mb</name><value>4096</value><name>mapreduce.reduce.memory.mb</name><value>8192</value> |
Each Container will run JVMs for the Map and Reduce tasks. The JVM
heap size should be set to lower than the Map and Reduce memory defined
above, so that they are within the bounds of the Container memory
allocated by YARN.
In
mapred-site.xml:
1
2
3
4
| <name>mapreduce.map.java.opts</name><value>-Xmx3072m</value><name>mapreduce.reduce.java.opts</name><value>-Xmx6144m</value> |
The above settings configure the upper limit of the physical RAM that
Map and Reduce tasks will use. The virtual memory (physical + paged
memory) upper limit for each Map and Reduce task is determined by the
virtual memory ratio each YARN Container is allowed. This is set by the
following configuration, and the default value is 2.1:
In
yarn-site.xml:
1
2
| <name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value> |
Thus, with the above settings on our example cluster, each Map task
will get the following memory allocations with the following:
- Total physical RAM allocated = 4 GB
- JVM heap space upper limit within the Map task Container = 3 GB
- Virtual memory upper limit = 4*2.1 = 8.2 GB
With YARN and MapReduce 2, there are no longer pre-configured static
slots for Map and Reduce tasks. The entire cluster is available for
dynamic resource allocation of Maps and Reduces as needed by the job. In
our example cluster, with the above configurations, YARN will be able
to allocate on each node up to 10 mappers (40/4) or 5 reducers (40/8) or
a permutation within that.