Running Hadoop on Ubuntu Linux (Multi-Node Cluster)
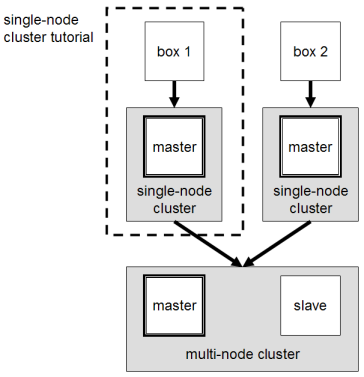
From single-node clusters to a multi-node cluster
We will build a multi-node cluster merge two or more single-node clusters into one multi-node cluster in which one Ubuntu box will become the designated master but also act as a slave , and the other box will become only a slave.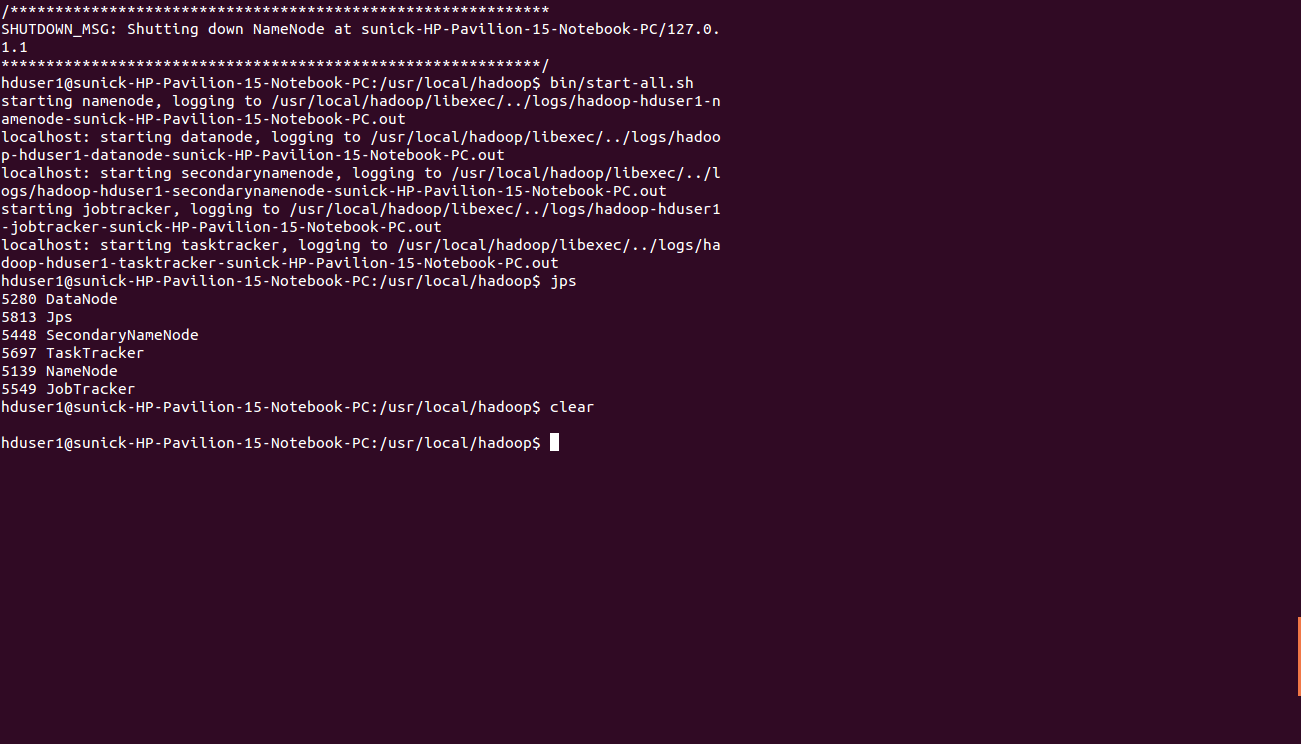
Prerequisites
Configuring single-node clusters first,here we have used two single node clusters. Shutdown each single-node cluster with the following commanduser@ubuntu:~$ bin/stop-all.sh
Networking
- The easiest is to put both machines in the same network with regard to hardware and software configuration.
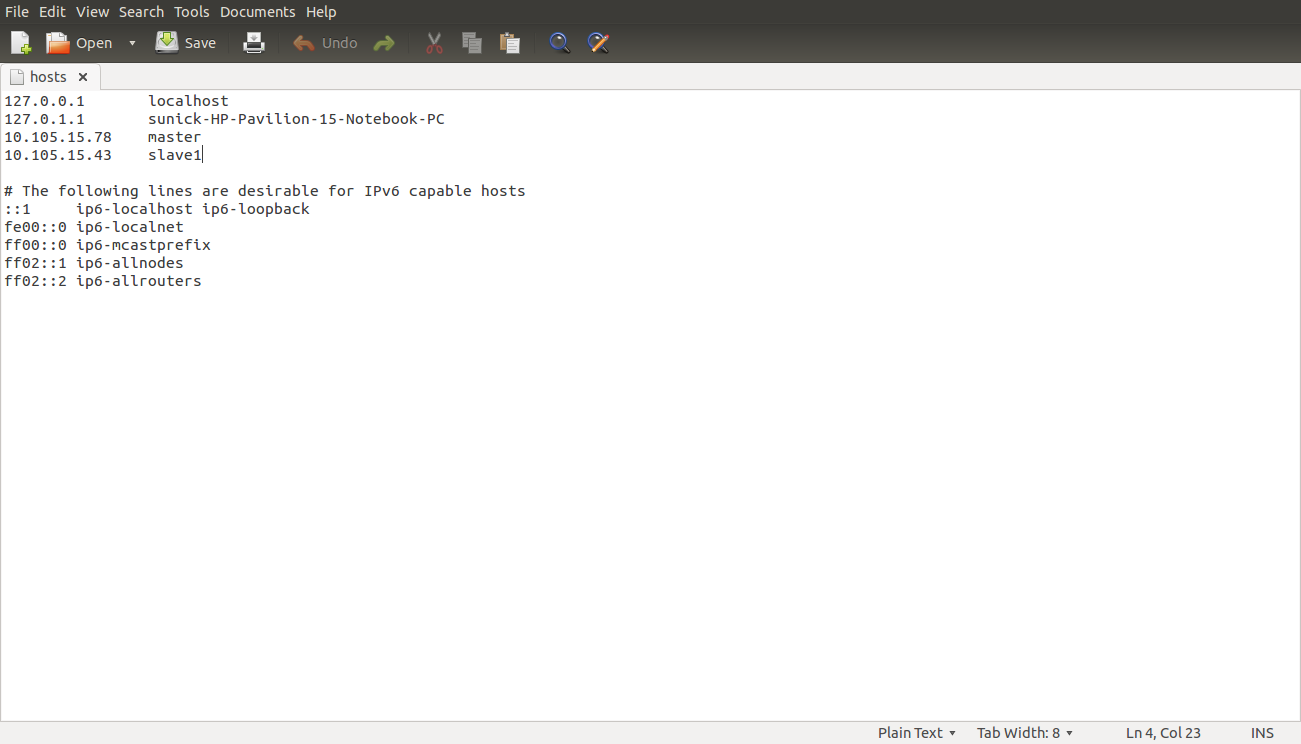
- Update /etc/hosts on both machines .Put the alias to the ip addresses of all the machines. Here we are creating a cluster of 2 machines , one is master and other is slave 1
hduser@master:$ cd /etc/hosts
- Add the following lines for two node cluster
10.105.15.78 master (IP address of the master node) 10.105.15.43 slave1 (IP address of the slave node)
SSH access
The hduser user on the master (aka hduser@master) must be able to connect:- to its own user account on the master - i.e. ssh master in this context.
- to the hduser user account on the slave (i.e. hduser@slave1) via a password-less SSH login.
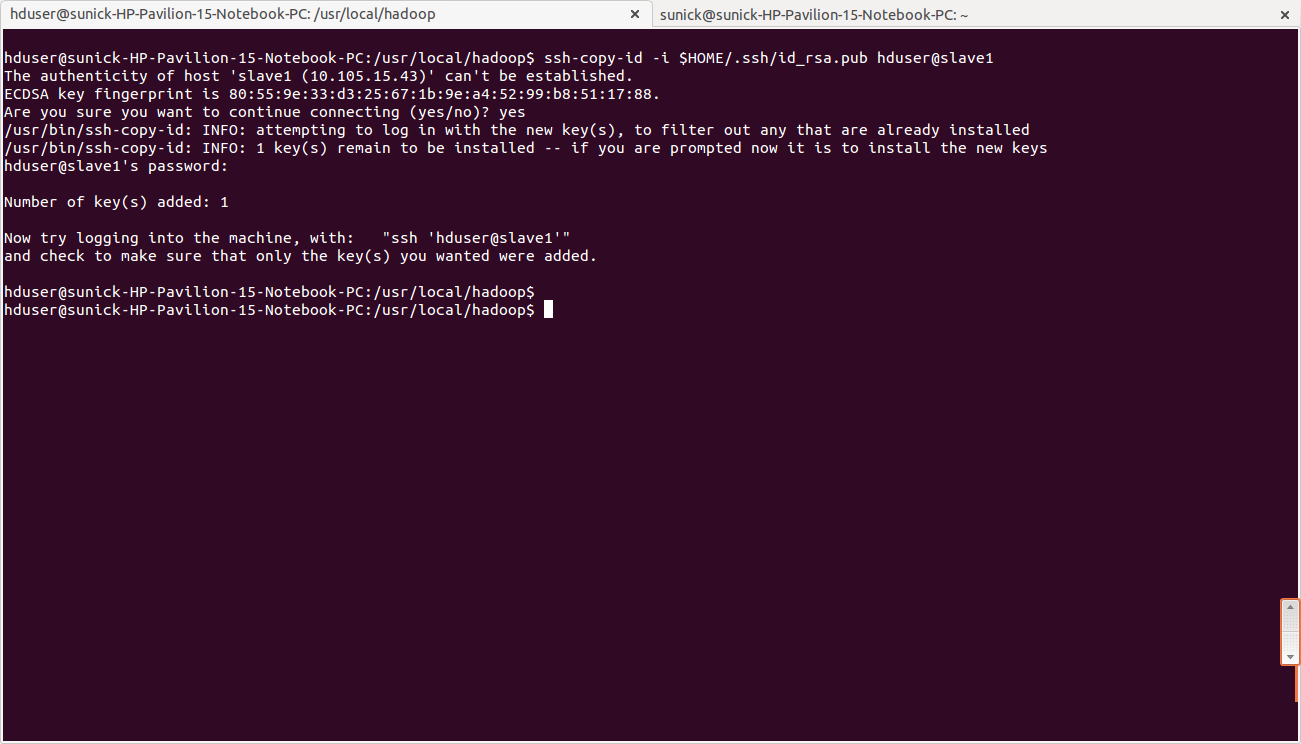
- Add the hduser@master public SSH key using the following command
hduser@master:~$ ssh-copy-id -i $HOME/.ssh/id_rsa.pub hduser@slave1
- Connect with user hduser from the master to the user account hduser on the slave.
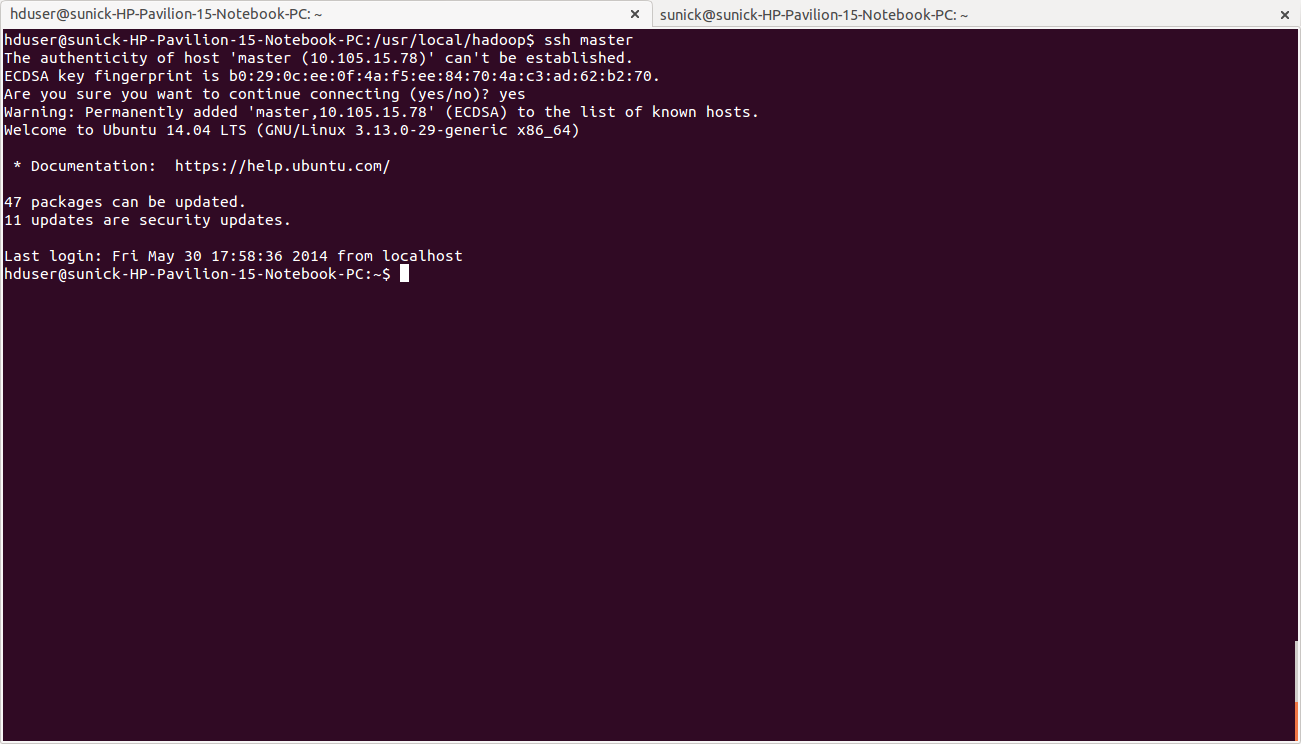
- From master to master
hduser@master:~$ ssh master
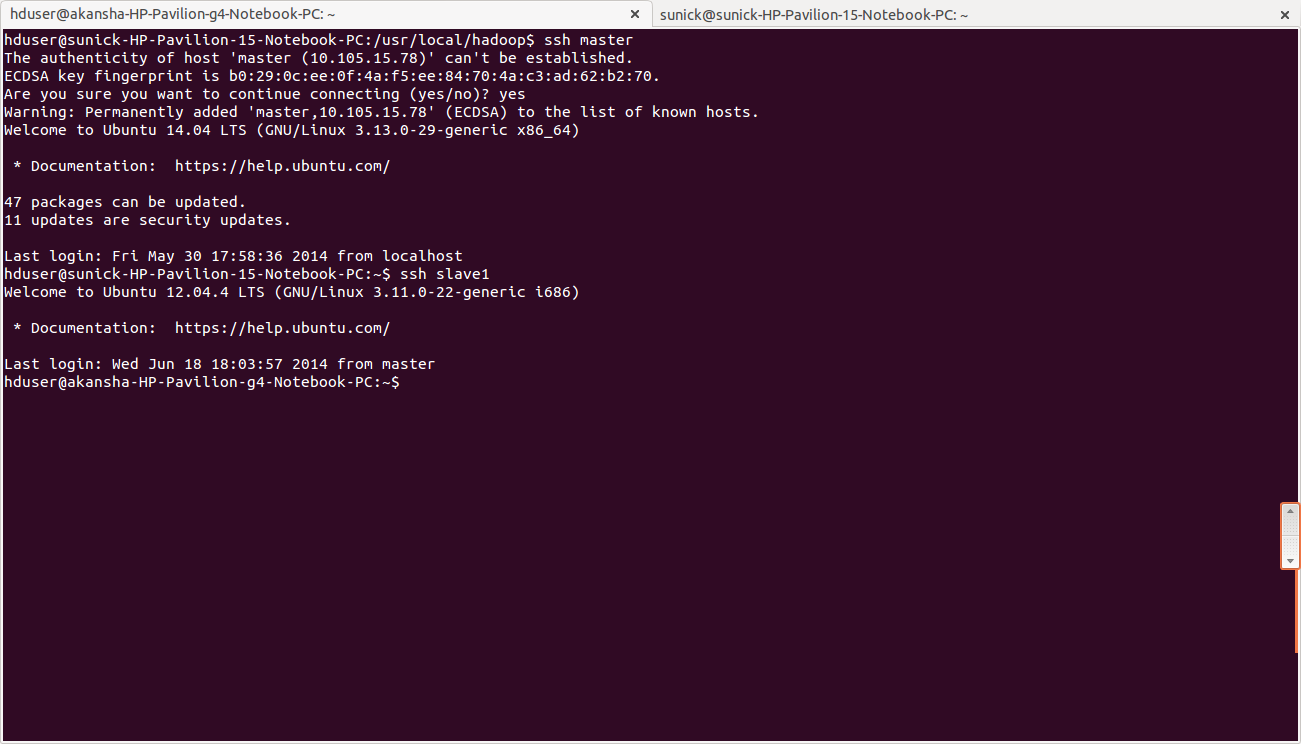
- From master to slave
hduser@master:~$ ssh slave1
Hadoop
Cluster Overview
This will describe how to configure one Ubuntu box as a master node and the other Ubuntu box as a slave node.Configuration
conf/masters
The machine on which bin/start-dfs.sh is running will become the primary NameNode. This file should be updated on all the nodes. Open the masters file in the conf directoryhduser@master/slave :~$ /usr/local/hadoop/conf
hduser@master/slave :~$ sudo gedit masters
Master
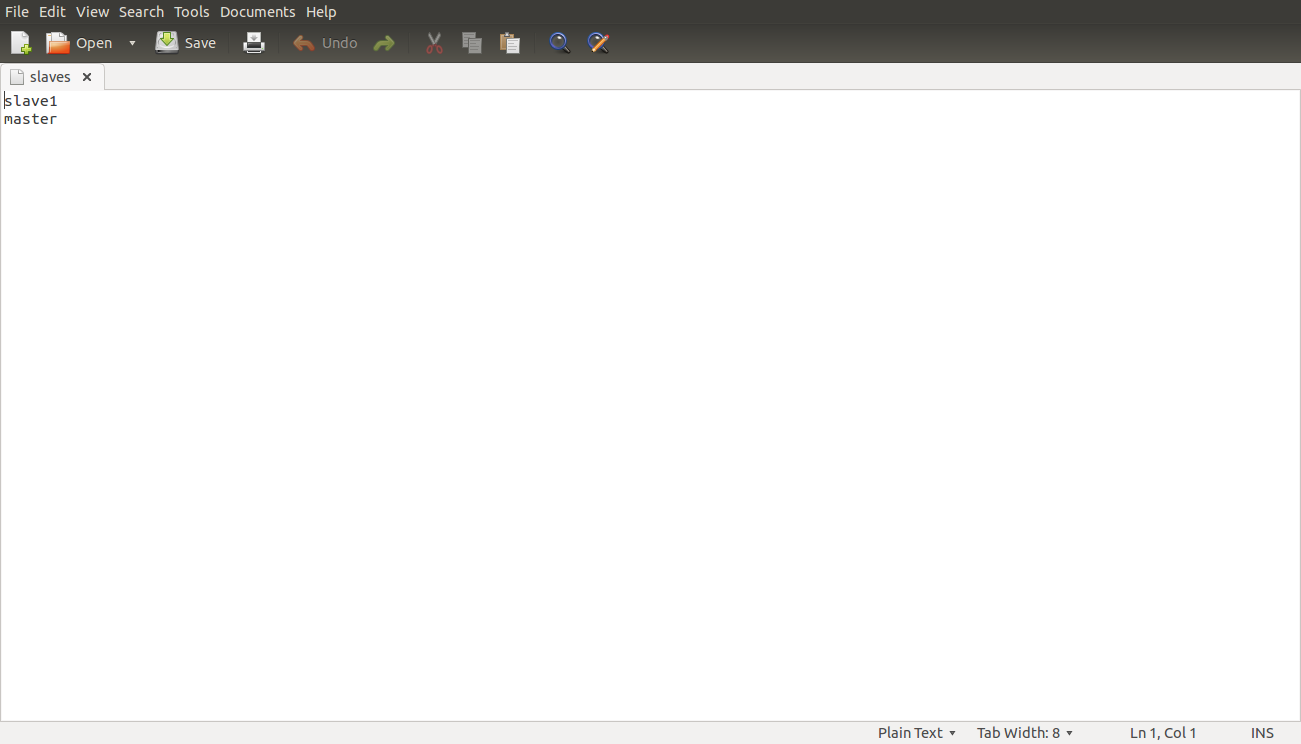
conf/slaves
This file should be updated on all the nodes as master is also a slave. Open the slaves file in the conf directoryhduser@master/slave:~/usr/local/hadoop/conf$ sudo gedit slaves
Master
Slave1
conf/*-site.xml (all machines)
Open this file in the conf directoryhduser@master:~/usr/local/hadoop/conf$ sudo gedit core-site.xml
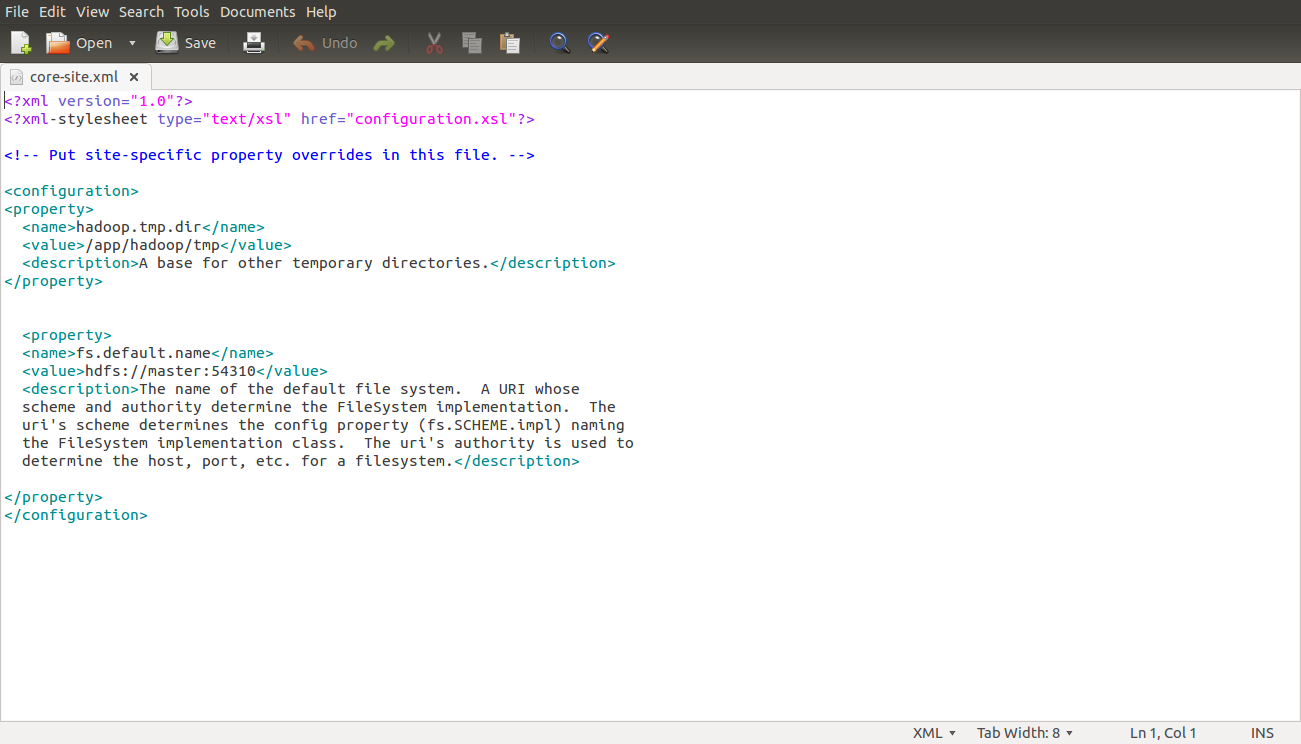
conf/core-site.xml (ALL machines .ie. Master as well as slave)
<property>
<name>fs.default.name</name>
<value>hdfs://master:54310</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
conf/mapred-site.xml
Open this file in the conf directoryhduser@master:~$ /usr/local/hadoop/conf
hduser@master:~$ sudo gedit mapred-site.xml
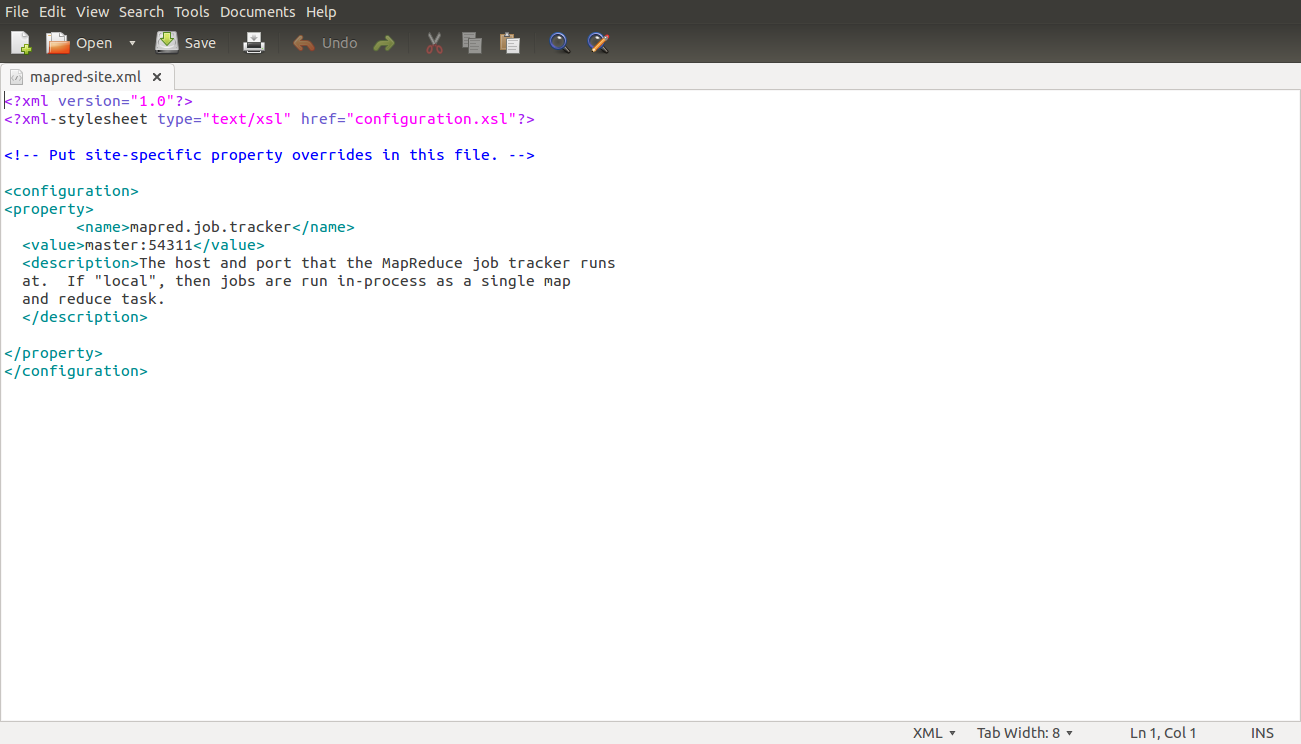
conf/mapred-site.xml (ALL machines)
<property>
<name>mapred.job.tracker</name>
<value>master:54311</value>
<description>The host and port that the MapReduce job tracker runs
at. If "local", then jobs are run in-process as a single map
and reduce task.
</description>
</property>
conf/hdfs-site.xml
Open this file in the conf directoryhduser@master:~$ /usr/local/hadoop/conf
hduser@master:~$ sudo gedit hdfs-site.xml
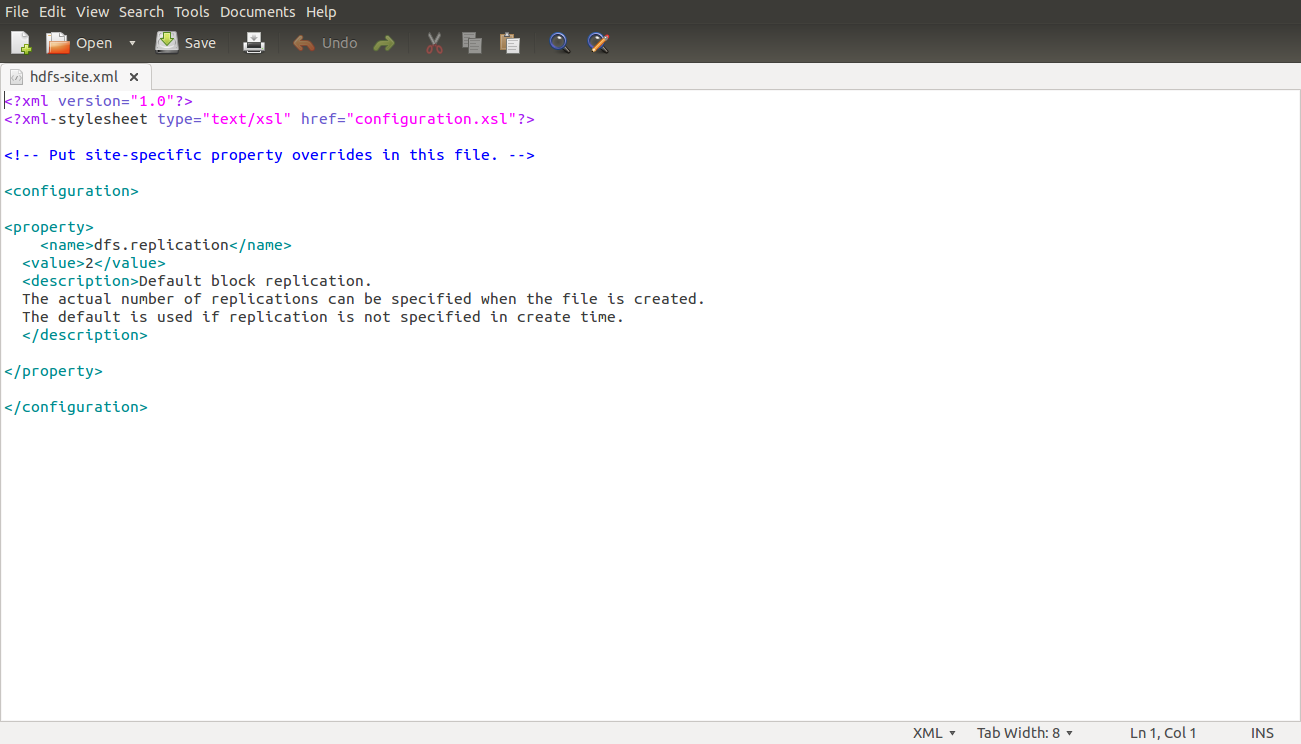
conf/hdfs-site.xml (ALL machines)
Changes to be made<property>
<name>dfs.replication</name>
<value>2</value>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
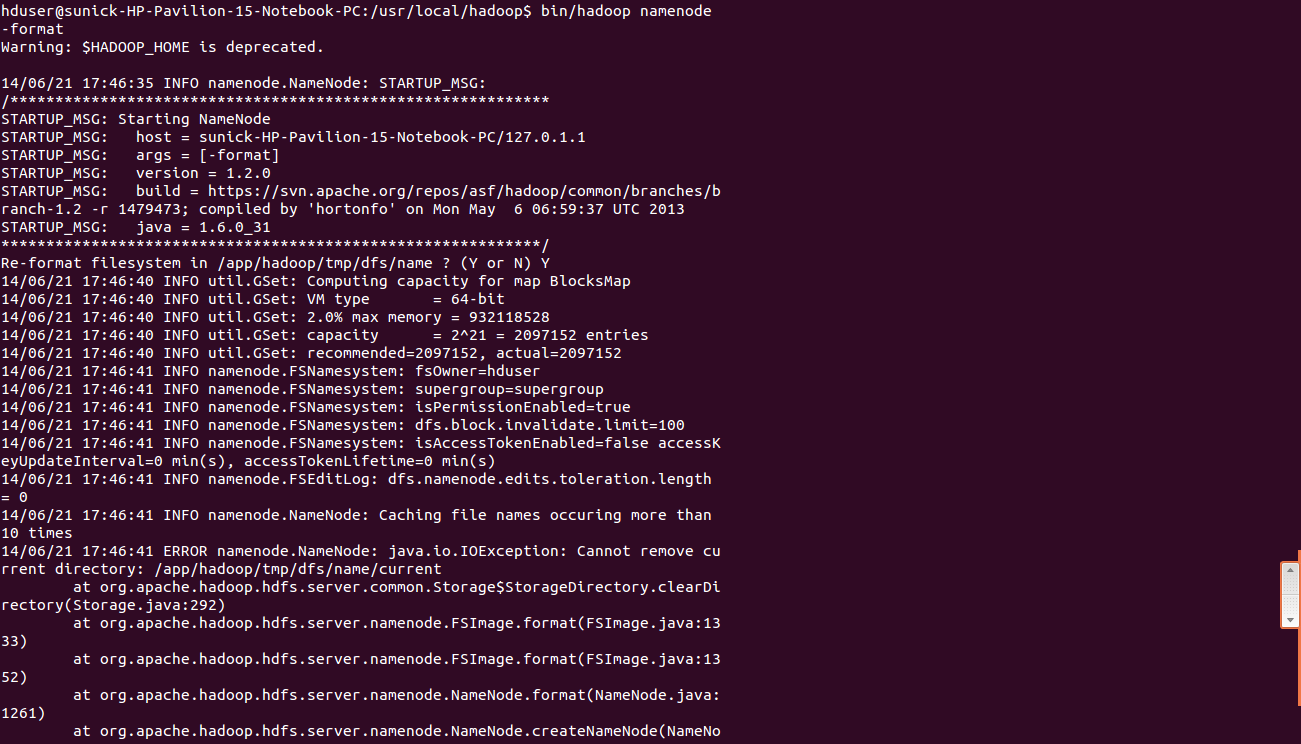
Formatting the HDFS filesystem via the NameNode
Format the cluster’s HDFS file systemhduser@master:~/usr/local/hadoop$ bin/hadoop namenode -format
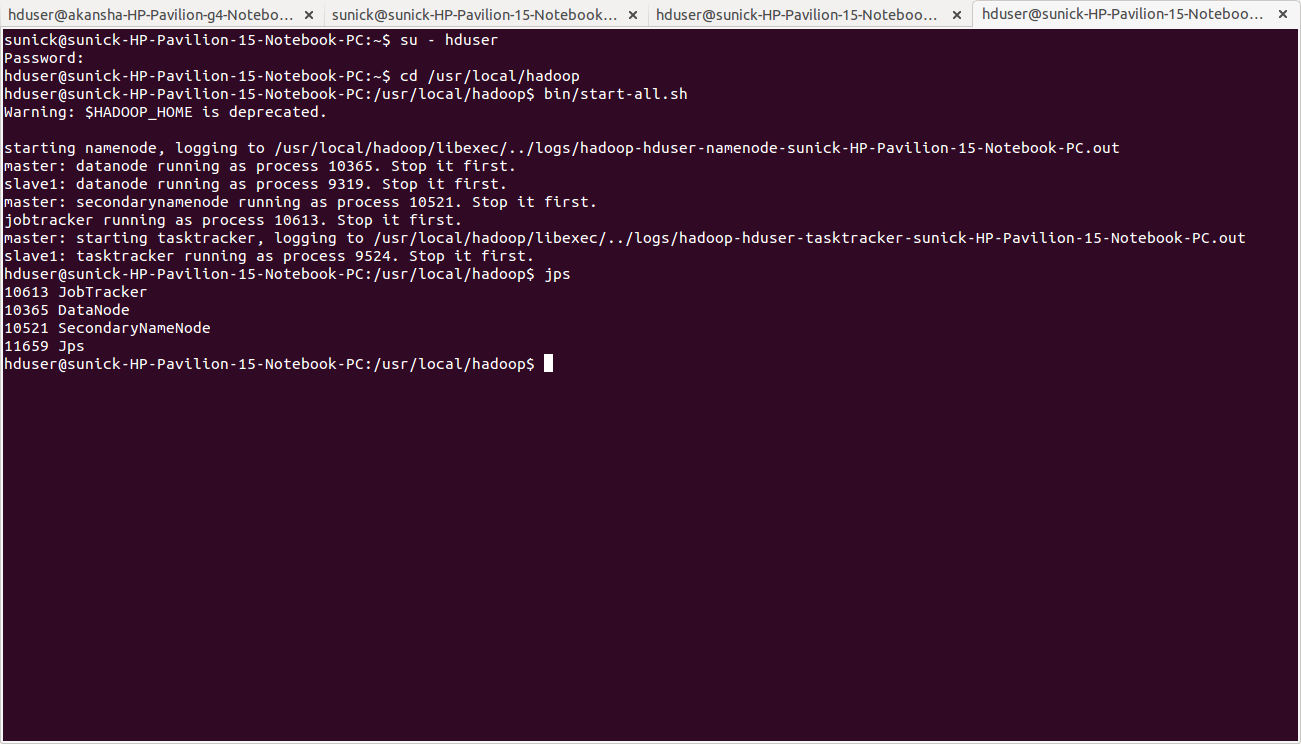
Starting the multi-node cluster
Starting the cluster is performed in two steps.- We begin with starting the HDFS daemons: the NameNode daemon is started on master, and DataNode daemons are started on all slaves (here: master and slave).
- Then we start the MapReduce daemons: the JobTracker is started on master, and TaskTracker daemons are started on all slaves (here: master and slave).
hduser@master:~$ /usr/local/hadoop
hduser@master:~$ bin/start-all.sh
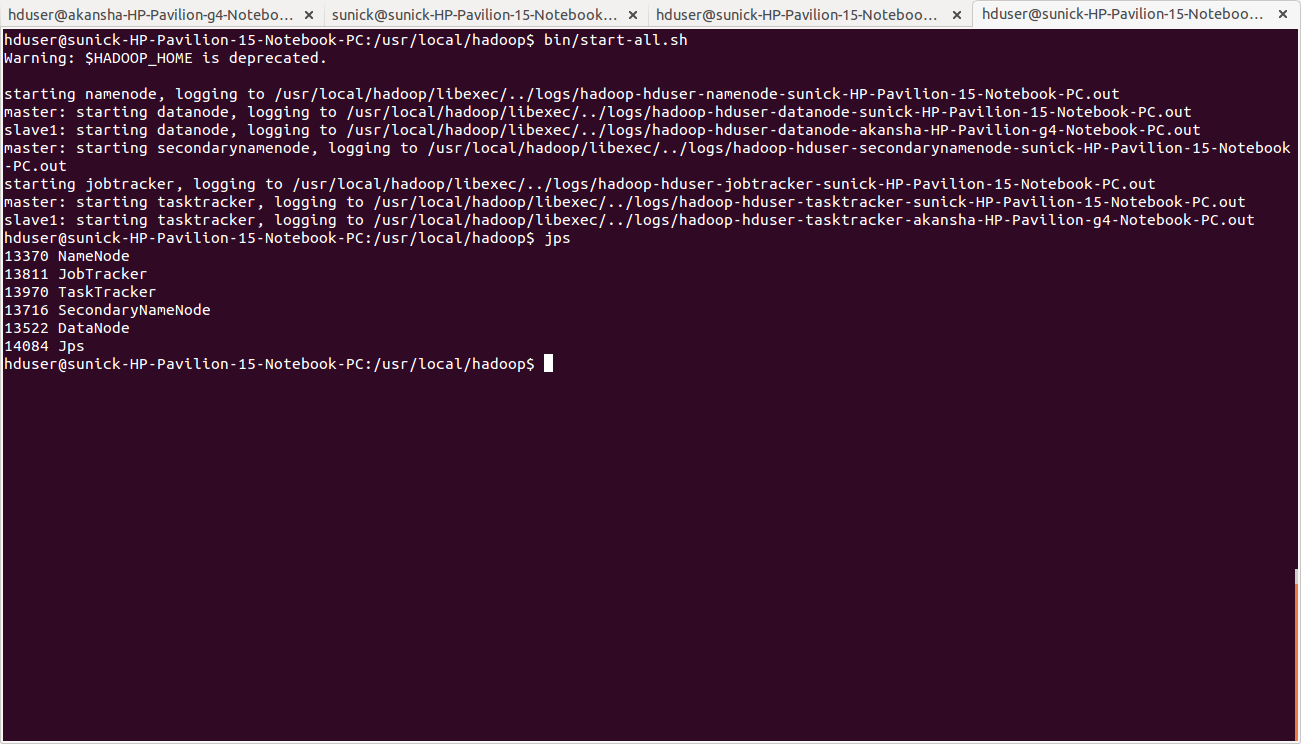
- The NameNode daemon is started on master, and DataNode daemons are started on all slaves (here: master and slave).
- The JobTracker is started on master, and TaskTracker daemons are started on all slaves (here: master and slave)
hduser@master:~$ jps
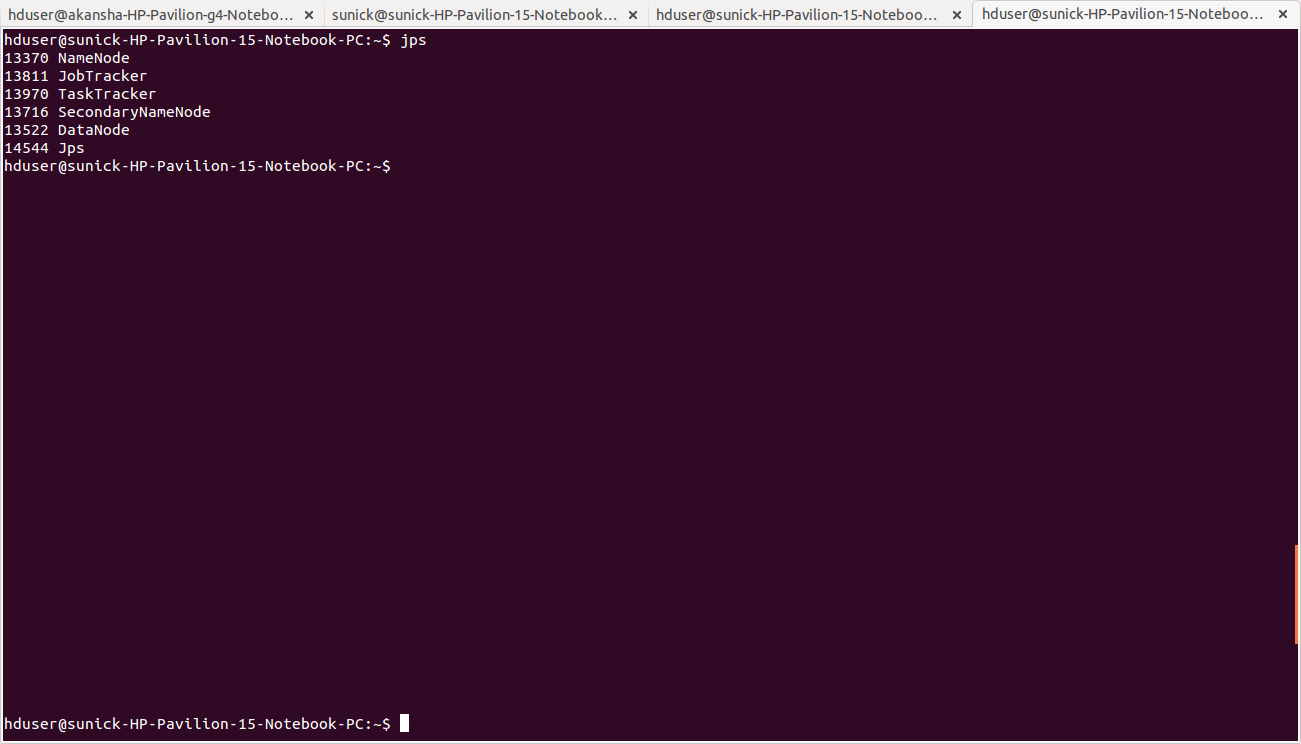
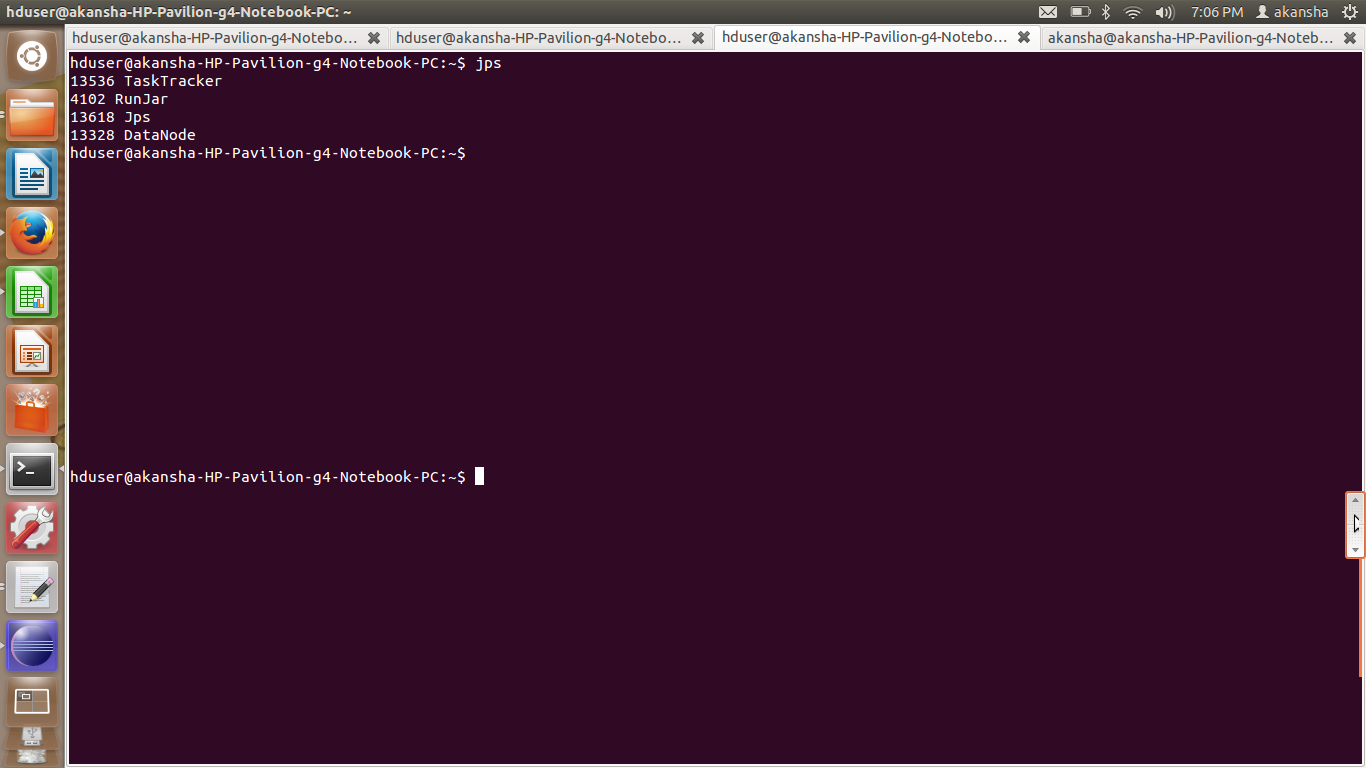
hduser@slave:~/usr/local/hadoop$ jps
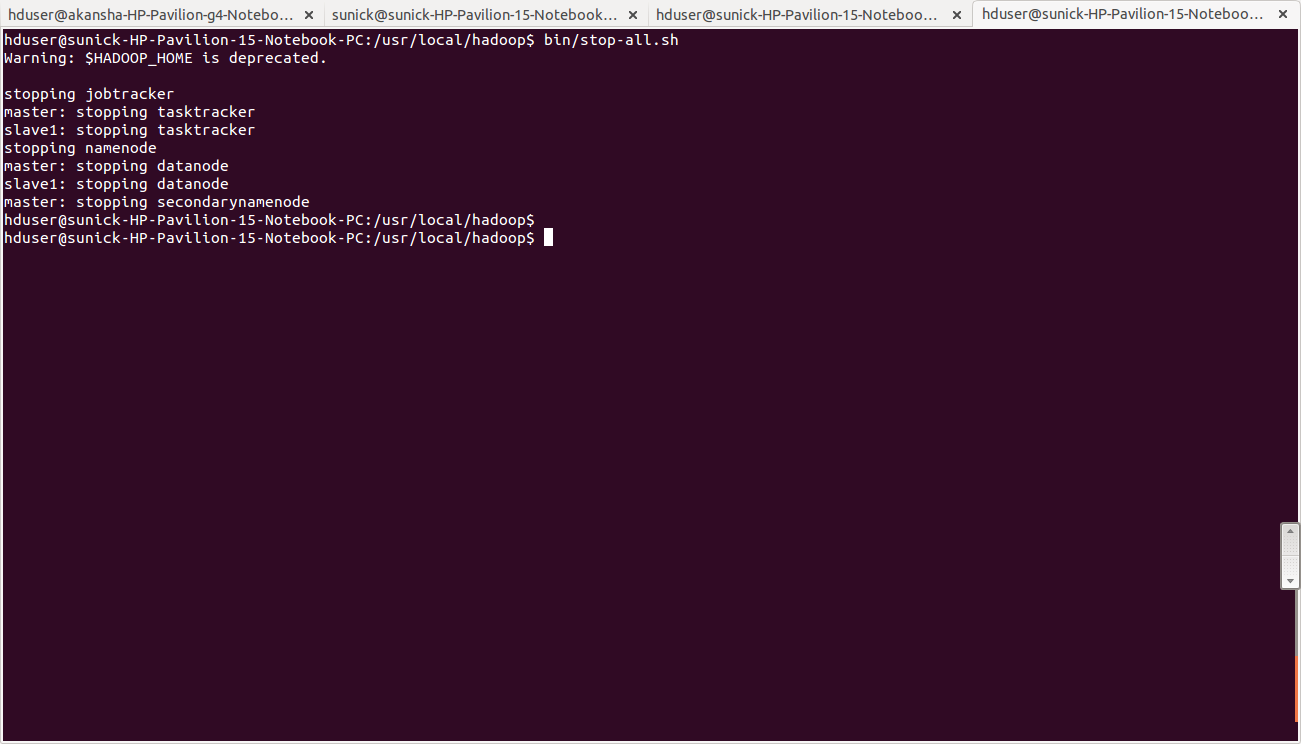
Stopping the multi-node cluster
To stop the multinode cluster , run the following command on master pchduser@master:~$ cd /usr/local/hadoop
hduser@master:~/usr/local/hadoop$ bin/stop-all.sh
ERROR POINTS:
-
- Number of slaves = Number of replications in hdfs-site.xml
- also number of slaves = all slaves + master(if master is also considered to be a slave)
- When you start the cluster, clear the tmp directory on all the nodes (master+slaves) using the following command
hduser@master:~$ rm -Rf /app/hadoop/tmp/*
- Configuration of /etc/hosts , masters and slaves files on both the masters and the slaves nodes should be the same.
- If namenode is not getting started run the following commands:
- To give all permissions of hadoop folder to hduser
hduser@master:~$ sudo chmod -R 777 /app/hadoop
- This command deletes the junk files which gets stored in tmp folder of hadoop
hduser@master:~$ sudo rm -Rf /app/hadoop/tmp/*